







-


-
- 요16:16-24
- 김덕종
- 2026.07.12



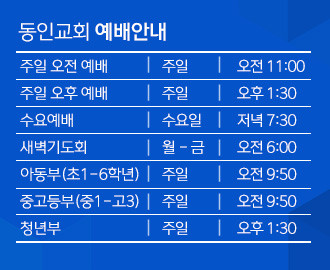
2026.07.16
역대상 16장_일상의 삶
예전에 아프리카 부룬디로 단기선교를 갔던 이야기를 말씀드린 적이 있습니다.선교단체 후배들과 함께 거의 4주 정도 아프리카의 부룬디에서 단기선교 사역을 했습니다.사역을 마칠 때 쯤 다같이 모여서 그동안 사역했던 소감을 나누었습니다.소감을 나누는데 많은 후배들이 한국에 돌아가는 것보다 여기서 사역하는 것이 더 좋다는 말을 했습니다.그 때 사역을 생각해보면 꽤 힘든 사역이었습니다.거의 매일 오전과 오후 하루 두 군데 교회를 다니면서 성경학교 사역을 했습니다.많이 모이는 교회는 아이들이 거의 300-400명 정도 모였습니다.보통 아침 6시에 일어나 예배하고 사역을 나갔다 들어오면 저녁이 다 되었습니다.대부분의 교회가 흙바닥이라 온 몸은 땀에 먼지 투성이었습니다. 순서대로 샤워를 해야 해서 샤워도 하지 못하고 저녁을 먹기도 했습니다.저녁을 먹고 매일 저녁 특강을 들었습니다.특강이 끝나고 다음날 사역준비를 하면 밤 11시, 12시가 넘기 일쑤였습니다.다음날은 다시 6시 기강,여러모로

